Linux has been a first class networking citizen for quite a long time now. Every system running a Linux kernel out of the box has at least three routing tables and is supporting multiple mechanisms for advanced routing features – from policy based routing (PBR), to VRFs(-lite), and network namespaces (NetNS). Each of these provide different levels of separation and features, with PBR being the oldest one and VRFs the most recent addition (starting with Kernel 4.3).
This article is the third part of the Linux Routing series and will provide an overview on Virtual Routing and Forwarding (VRFs) and its applications. The first post in the series about Linux Routing Fundamentals covers the basics and plumbings of Linux routing tables, what happens when an IP packet is sent from or through a Linux box, and how to figure out why. The second post on Policy-based routing covers the concepts and plumbing of PBR on Linux. Both are a good read if you don’t feel familiar with these topics and provide knowledge about corner stones referenced here.
Virtual Routing and Forwarding
Virtual Routing and Forwarding (VRF) is another mighty feature of the Linux network stack and has been added more recently, compared to PBR. It has been introduced in steps in Kernel version 4.3 – 4.8 and I’d consider it mature since v4.9, which has been around for quite a while.
VRFs are a concept long known from networking hardware and provide independent routing instances and therefore Layer 3 separation. This means that the same prefixes can be used in different VRFs and they don’t overlap or interact with each other.
But wait, Linux had different routing tables before already, right? Yes, correct, and VRFs are using different routing tables, with each VRF mapping to exactly one routing table. The difference is that any given interface is associated to exactly one VRF, and traffic arriving on an interface in VRF A will never reach VRF B, unless explicitly configured (route leaking). By default all interfaces of a Linux system (in the same NetNS) are part of the main VRF, which does not need special configuration.
This is a less strict separation than Network Namespaces, as they provide separation on Layer 1 – one interface can only be in one NetNS, which can have its own set of VRFs and PBR rules.
Common use cases for VRFs are separate connections to an Out-of-band management network, L3-VPNs (usually in combination with MPLS), or separation between an internal network and the Internet.
Practical use in Freifunk Hochstift network
For distributed networks, like the Freifunk Hochstift infrastructure, which don’t have direct connectivity between all islands but rather rely on tunnels over the Internet for interconnections, it’s beneficial to have a concept of internal and external.
In the classical Freifunk approach, policy-based routing has been used with a second table for the internal network, which also held all routes generally present in the main table. This was done using a bird pipe protocol, which synchronized everything besides the default route. All external facing connections were done regularly using the main table and the second table contained a separate default route for the client traffic, which used tunnels to leave the network. This had the drawback of being only a soft separation and leaking ICMP errors into the Internet and falling back to the main default route, in cases the default route in the second table disappeared. When doing a redesign of the network, this was one of the issues I wanted to tackle, and the solution are VRFs.
Today the main routing table / VRF is considered internal, most devices just use the main VRF and don’t have any special handling at all. Only core and edge routers, interconnecting sites or providing connectivity to the Internet have a second VRF vrf_external, which holds all externally facing interfaces. This concept allows strict separation and only requires special config on a few devices, which need the 2nd VRF.
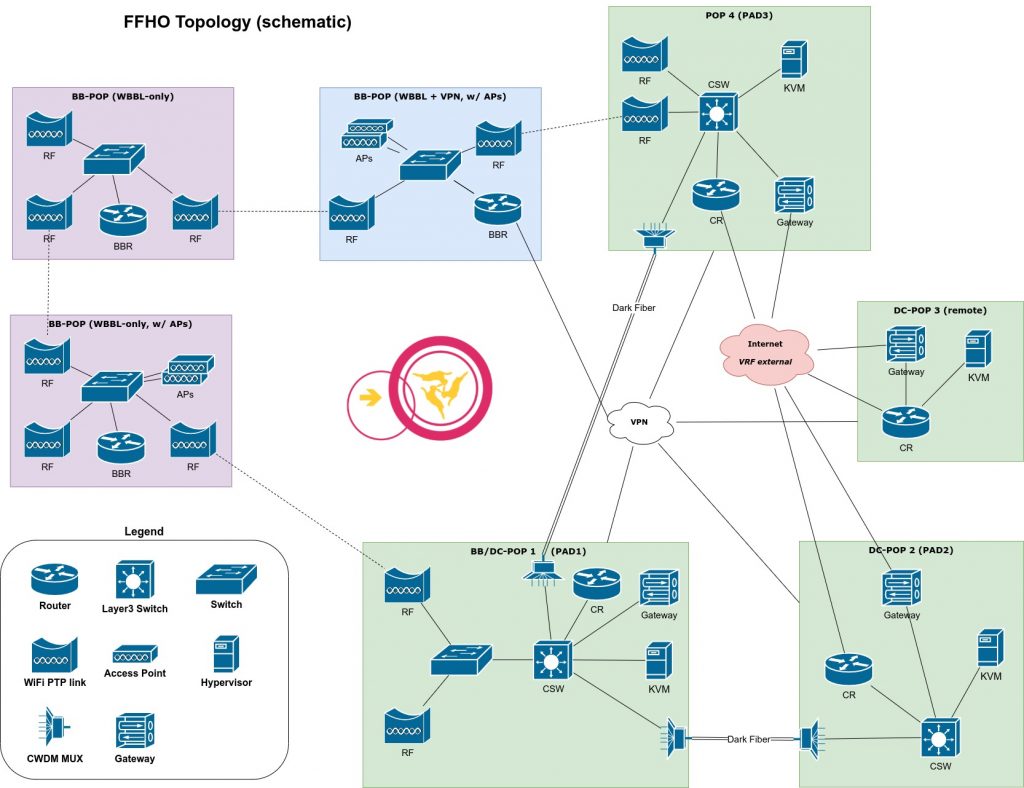
All tunnels are connected to send and receive encapsulated packets using the external VRF (red Internet cloud), and the tunnel endpoints end within the main VRF. See the VRF applications section for more thoughts on tunnels and how to configure things.
Configuring VRFs on Linux
On Linux, a VRF is represented by a special network interface, which is associated to a routing table. It can be created using ip link, e.g. with
# ip link add vrf_external type vrf table 1023
or, on Debian-based systems, by using ifupdown2 / ifupdown-ng, e.g. using the following configuration
auto vrf_external
iface vrf_external
vrf-table 1023
To add an interface to a VRF you technically have to set the VRF as its master device, like adding an interface to a bond or bridge. There’s also an option to set the VRF explicitly, using the vrf attribute, e.g.
# ip link set eth0 master vrf_external # generic
# ip link set eth0 vrf vrf_external # VRF specific
or, by using ifupdown2 / ifupdown-ng, e.g. using the following configuration (with an existing interface stanze for the VRF interface like above)
auto eth0
iface eth0
address 2002:db8:23:42::2/64
gateway 2001:db8:23:42::1/64
vrf vrf_external
Note that when you assign an interface to a VRF, any device route, e.g. for the 2002:db8:23:42::/64 prefix assigned in the example above, moves from table main and local into the VRF table, e.g. table 1023.
Under the hood / plumbing
Routes within a VRF can be listed by either ip route show vrf <VRF> or ip route show table <VRF table ID>, yielding slightly different results. IPv4 example:
$ ip r s vrf vrf_external
default via 192.0.2.1 dev eth0 metric 1
192.0.2.0/24 dev eth0 proto kernel scope link src 192.0.2.42
$ ip r s table 1023
default via 192.0.2.1 dev eth0 metric 1
broadcast 192.0.2.255 dev eth0 proto kernel scope link src 192.0.2.42
192.0.2.0/24 dev eth0 proto kernel scope link src 192.0.2.42
local 192.0.2.42 dev eth0 proto kernel scope host src 192.0.2.42
broadcast 192.0.2.255 dev eth0 proto kernel scope link src 192.0.2.42
The same is true for IPv6:
$ ip -6 r s vrf vrf_external
anycast 2001:db8:23:42:: dev eth0 proto kernel metric 0 pref medium
2002:db8:23:42::/64 dev eth0 proto kernel metric 256 linkdown pref medium
anycast fe80:: dev eth0 proto kernel metric 0 pref medium
fe80::/64 dev eth0 proto kernel metric 256 pref medium
multicast ff00::/8 dev eth0 proto kernel metric 256 pref medium
default via 2001:db8:23:42::1 dev eth0 metric 1 pref medium
$ ip -6 r s table 1023
anycast 2001:db8:23:42:: dev eth0 proto kernel metric 0 pref medium
local 2001:db8:23:42::2 dev eth0 proto kernel metric 0 pref medium
2002:db8:23:42::/64 dev eth0 proto kernel metric 256 linkdown pref medium
anycast fe80:: dev eth0 proto kernel metric 0 pref medium local fe80::222:19ff:fe65:b835 dev eth0 proto kernel metric 0 pref medium
fe80::/64 dev eth0 proto kernel metric 256 pref medium
multicast ff00::/8 dev eth0 proto kernel metric 256 pref medium
default via 2001:db8:23:42::1 dev eth0 metric 1 pref medium
The attentive reader will notice that the table view also shows routes, which usually would end up in table local, while the VRF view does only show routes, which usually would end up in the main table.
So, how do packets end up in a VRF? Remember those PBR rules we talked about in the previous post? Once you add a VRF, the kernel (since v4.8) automatically adds a “magic” rule into the mix:
$ ip rule
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default
This rule will match any packet arriving on a device associated to a VRF, and the Linux kernel will forward those packets using the table associated with the VRF.
Note: As this still is using the PBR framework and there is no matching route in the table associated to a given VRF, rule processing will fall through to following rules! To make sure you’re not leaking traffic, make sure you always have a default route in your VRF table, e.g. by statically adding an default route with type unreachable with a high metric, e.g.
# ip route add unreachable default metric 10000 vrf vrf_external
L3mdev
With VRFs came a concept of a Layer 3-Master-Device (l3mdev), which shows up in above PBR rule output, but also in sysctl settings, and around sockets.
By default, packets sent from applications running on a Linux machine will use the main VRF – mostly meaning the main table – to reach their destination. With VRFs, it can happen that a packet is received within a VRF and ideally we want it to be routed back using the same VRF. By default, and application receiving a packet would not know about any VRF associations and the kernel would blissfully route any response packets using the main VRF, which most likely won’t work. But worry not, there’s help in form of sysctl settings:
# tcp_l3mdev_accept - BOOLEAN
#
# Enables child sockets to inherit the L3 master device index.
# Enabling this option allows a "global" listen socket to work
# across L3 master domains (e.g., VRFs) with connected sockets
# derived from the listen socket to be bound to the L3 domain in
# which the packets originated. Only valid when the kernel was
# compiled with CONFIG_NET_L3_MASTER_DEV.
#
# Default: 0 (disabled)
net.ipv4.tcp_l3mdev_accept = 1
The same setting exists for UDP and raw sockets (net.ipv4.udp_l3mdev_accept and net.ipv4.raw_l3mdev_accept respectively).
With at least the TCP-one activated, applications such as SSH or nginx will work throughout all VRFs. Packets received via an OOBM VRF for example, will be marked as such and the kernel will the any replies on that socket using the same OOBM VRF. There should be no harm in activating this setting when working with VRFs.
Working with VRFs
When working with VRFs you sometimes need to debug things, but worry not, there are options!
For starters, there’s an ip vrf sub-command, with ip vrf show and ip vrf exec being the most relevant ones. Check the ip-vrf(8) man-page for further commands and details.
To get an overview of all locally configured VRFs and their respective routing tables, you could either use ip [-brief] link show type vrf, or use the much nicer output of ip vrf show including the VRF’s table IDs:
# ip link show type vrf
12: vrf_external: mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether e6:88:f3:23:b5:b3 brd ff:ff:ff:ff:ff:ff
21: vrf_oobm_ext: mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 2a:bb:3b:b3:a1:d5 brd ff:ff:ff:ff:ff:ff
22: vrf_oobm: mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 2a:68:b1:25:60:df brd ff:ff:ff:ff:ff:ff
# ip -br link show type vrf
vrf_external UP e6:88:f3:23:b5:b3
vrf_oobm_ext UP 2a:bb:3b:b3:a1:d5
vrf_oobm UP 2a:68:b1:25:60:df
# ip vrf show
Name Table
vrf_external 1023
vrf_oobm_ext 1101
vrf_oobm 1100
Any command run on a Linux system will, by default, be run from the main VRF and therefor use the main routing table (if no fancy PBR rules are in place). When working with VRFs, it’s useful to verify reachability from a given VRF or run a command (apt, wget, …) from within a VRF.
Some commands directly have support for VRFs or working with a given interface, which potentially can be used to make the command use a given VRF.
To do a route lookup using a given VRF, ip route get support a parameter vrf, e.g.
$ ip r g 1.1.1.1
1.1.1.1 via 203.0.113.128 dev wg-cr04 src 203.0.113.23 uid 0
cache
$ ip r g 1.1.1.1 vrf vrf_external
1.1.1.1 via 192.0.2.1 dev eth0 table 1023 src 192.0.2.42 uid 0
cache
The ping command has a parameter -I interface, with interface being either an address, an interface name or a VRF name (quoted from the ping(8) man-page). So following the example above, you can see a difference in latency and hops indicating different paths to the same destination.
$ ping -c 3 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=58 time=172 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=58 time=127 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=58 time=56.4 ms
--- 1.1.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 56.440/118.464/171.986/47.553 ms
$ ping -c 3 1.1.1.1 -I vrf_external
ping: Warning: source address might be selected on device other than: vrf_external
PING 1.1.1.1 (1.1.1.1) from 192.0.2.42 vrf_external: 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=56 time=20.2 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=56 time=19.3 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=56 time=19.0 ms
--- 1.1.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 19.017/19.516/20.222/0.513 ms
The classical traceroute offers an -i interface parameter, which allows tracing routes using a given VRF. I sadly didn’t find a native way for mtr to do a trace from within a VRF, however we can still make it use a VRF, by using a more generic way.
If the desired command does not have native support to bind to an interface/VRF, it can be invoked through ip vrf exec VRF cmd to ensure any network activity from the given cmd will use the given VRF. To encourage mtr to start a trace from within vrf_external, we can invoke it using
# ip vrf exec vrf_external mtr 1.1.1.1
It might also come in handy to download or install something over an OOBM link when the main uplink has failed, which might result in an invocation of apt update using vrf_oobm
# ip vrf exec vrf_oobm apt update
Connecting VRFs
When there’s separation, there sometimes also is the need to bring things back together, at least partially 🙂
There are – at least – two ways to let packets traverse between VRFs, either by plugging a virtual “cable” or by leaking routes between the VRFs. In classical network terms the first one is similar to a “hyper loop”, although happening in software, the latter exists as-is in hardware routers.
VEth pair
Linux offers support for virtual Ethernet (veth) interfaces, which always come in pairs. You can think of them as a virtual network cable, which you can “plug” into bridges, VRFs, or even different Network Namespaces. As the name suggest they operate on Layer 2 and upwards.
To create a VEth path with interfaces VETH_END1 and VETH_END2 and plug VETH_END2 into vrf_external, you can either run
# ip link add VETH_END1 type veth peer name VETH_END2
# ip link set dev VETH_END2 master vrf_external
(IP address config and getting interfaces up left out for brevity)
or using ifupdown2*/ifupdown-ng with the following configuration
iface VETH_END1
address 198.51.100.0/31
address 2001:db8::1/126
link-type veth
veth-peer-name VETH_END2
iface VETH_END2
address 198.51.100.1/31
address 2001:db8::2/126
link-type veth
veth-peer-name VETH_END1
vrf vrf_external
with vrf_external defined separately, like above.
* Support to set the veth-peer-name was merged with PR25, I’m unsure if it still works.
Now you can directly connect from one VRF to the other (main <-> vrf_external) and could set routes, e.g. using
# ip route add 192.0.2.0/24 via 198.51.100.1
# ip route add 203.0.113.0/24 via 198.51.100.0 vrf vrf_external
with 192.0.2.0/24 being the external subnet used above and 203.0.113.0/24 being an internal subnet, somehow connected to the local box.
Besides using static routes, which could be done without a VRF pair – see below – it would also be possible to use a routing daemon like bird to exchange routes between VRFs, even by speaking to itself 🙂
Route Leaking
To achieve the same behavior as in the example above, we could also use two routes which point to the other VRF or the loopback interface within the main VRF as target, e.g.
# ip route add 192.0.2.0/24 dev vrf_external
# ip route add 198.51.100.0/24 dev eth1 vrf vrf_external
with eth1 being part of the main VRF.
VRF Applications
Reverse-proxy into the internal network
With the above approach in place, there might arise the need to expose web services running internally to the outside world. This can be done by using a machine with
- two interfaces, one in the internal as well as external VRF,
- a reverse proxy, e.g. nginx, listening on an internal and external IP
tcp_l3mdev_acceptset to1
et voilà, the proxy can serve requests from external and internal clients.
VRFs and tunnels
GRE
A lot of Freifunk community networks use GRE tunnels to connect to the Freifunk Rheinland backbone over the Internet, so do we. GRE tunnels – as well as a lot of other tunnel flavors, including VXLAN – offer an attribute dev or physdev to configure which interface should be used to transmit and receive encapsulated packets. So using
# ip link add gre0 type gre remote ADDR local ADDR dev PHYS_DEV
it’s possible to create a new GRE tunnel gre0 which will use PHSY_DEV to send/receive packets. If PHYS_DEV is within a VRF, all encapsulated packets are sent/received using its VRF.
It’s also possible to place the gre0 interface inside a VRF, in case you want to route traffic through the tunnel using a VRF.
OpenVPN
The Freifunk Hochstift network made heavy use of OpenVPN some years ago, so it was only natural to want OpenVPN to leverage VRFs. It would be pretty straight forward to place the tap/tun device into a VRF once it has been created, however that would be the wrong around for the desired use case.
I’ve patched OpenVPN to support transmitting encapsulated packets through a VRF, using the --bind-dev parameter, which is part of OpenVPN 2.5 and above. See the previous post on OpenVPN and VRFs for details.
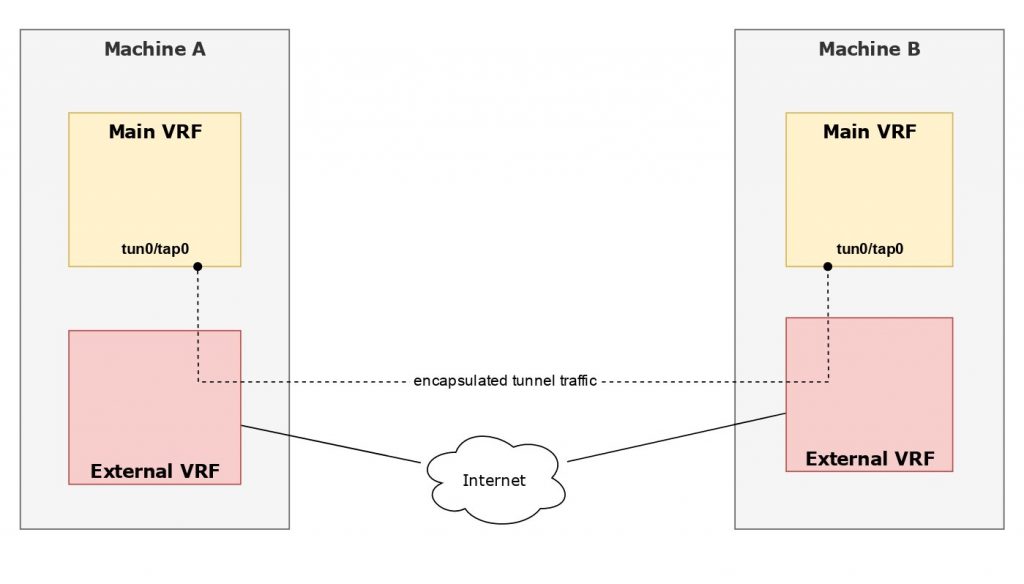
WireGuard
WireGuard does not allow binding to an interface or VRF, however you can build an VRF-like setup using fwmarks. I’ve written a separate article about WireGuard and VRFs.
VRFs + MPLS
Want to go one step further and bring MPLS into the mix to build an L3VPN setup using Linux?
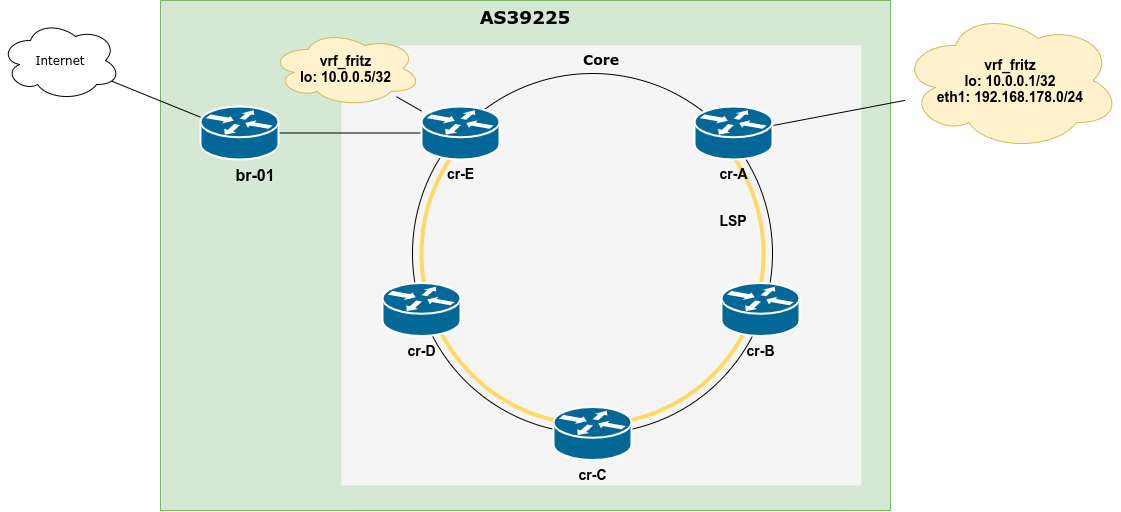
See my blog post about the MPLS Lab – Playing with static LSPs and VRFs on Linux for a hands-on guide. 🙂
Further Reading
- The Linux Kernel VRF documentaton
- Presentation from Cumulus Networks on Operationalizing VRF in the Data Center
- OpenVPN and VRFs
- Wireguard and VRFs
One thought on “Advanced Linux Routing – VRFs”