If you are like me and have some systems with fully encrypted disks, where you can’t or don’t want to be physically present for a system (re)boot, or which don’t have OOBM/KVM/CIMC access, this might be for you!
Having a look at how the generic disk decryption works on Debian-based systems, but likely also on others, is to add a script into the init-ramdisk (or initrd) which wraps a call to cryptsetup luksOpen for a given device(s).
So we can use the same mechanism to set up an SSH daemon within the initrd, configure the network so we can get administrative access, and then unlock the disks remotely. The only two things we have to do are to make sure all the plumbing is added to the initrd and the script is started before the regular interactive disk unlock script gets executed.
For Debian-based systems I’ve build this a while ago and finally Open Sourced it as fluffy-unluks on GitHub.
The add-unluks script set ups sshd and the required environment (NSS, etc.) for it to run as well as installing potentially needed Kernel modules for advanced network configs when building a new initrd.
The unluks script will be run on boot-up, configure the network as needed (including an LACP LAG and/or VLAN sub-interface, if desired), start the SSH server and wait for you to unlock the disks. If all configured disks have been unlocked – by checking for existing block devices or LVM volume groups – the temporary network configured is purged, sshd stopped and the system resumes the normal boot.
An optional safeword can be configured to instruct the unluks script to do nothing so the regular boot sequence will be used.
Although NetBox has a pretty nice data model and a lot of things found in common environments can be modeled pretty well, it sometimes reaches its limits. In such situations you’re faced with multiple options to go forward
Introduce (a number of) custom field(s) to extend the data model
Write a plugin to extend the data model (and logic)
Introduce a (set of) tag(s) to allow users to place bumper stickers on things
File a feature request to add some generic missing feature
In this post we’ll look into options for using Tags to denote characteristics of devices, VMs, interfaces, prefixes, IPs, etc.
Simple labels
Sometimes it’s enough to just label a device, an interfaces, etc. with a static bit of information. Examples would be
Enable backup on this device (e.g. tag backup)
Enable DHCP on this interface (e.g. tag DHCP)
Mark an interface as planned or offline (e.g. tags planned or offline)
Denote an interface is of type Wireguard (e.g. tag Wireguard)
etc.
For those cases you can create a tag, e.g. planned, and apply it to any interface which is configured in NetBox, should be configured on the device but isn’t connected yet, so that effectively you can push down (parts of) the interface configuration to the device but inhibit alarms for it being offline or IGP adjacencies being down. The same is true for device which need to be backed up, etc.
One way of thinking of these example is as a boolean switch, which is set to true if the tag is applied. This is easy for cases where the “false” value is the default, so only the outliers – meaning “true” values – need to be represented explicitly.
Semantic labels
But what to do when there is a need for a tri-state value, e.g. true, false, unset, with unset being the default?
One example would be a part of an SDN controller which figures out if uRPF should be enabled on a given interface or not. This usually can be done programmatically, but in some situations an explicit override may be required. That’s where – what I would call them – Semantic Labels come in!
This means, that we also put the value we want to assign a given label into the tag. In this case, we create two labels called urpf=on as well as urpf=off (or urpf=enable and urpf=disable as you fancy) and apply these to any interface requiring an explicit override. If no tag is present the code decides about the fate of uRPF.
Why not use custom fields?!
At this point you may be wondering “Why bother? Just create a custom field, you can provide the allowed options and get input validation for free!
The reason is that if you go down this path, you can create a fairly long list of custom fields in the UI (and API) which are likely not set for the majority of you interfaces (in this example). This creates clutter within the UI and is likely to confuse users, especially if you end up with a number of custom fields.
My rule of thumb is, that I only create a custom field if it’s relevant for all or a least the majority of entities of a given kind. For example, if you wanted to store the data center tier of all the DC (read: Sites) you are present in, it might make sense to store this information as a custom fields on the Site model, with a predefined list of values (1 – 4).
More examples
In the example above we could also have created two labels, e.g. uRPF enable and uRPF disable and let our automation handle the differentiation – which actually is how the FFHO SDN is built as of today.
For other bits of information, with more possible values, the benefits of the key=value approach can shine, for example if you want to
explicitly set the OSPF cost of an interface (e.g. ospf_cost=100)
store the maximum capacity of VRFs of a box (e.g. capacity=62 for a box with a Mellanox Spectrum 1 ASIC with a default + mgmt VRF in place)
Although I now prefer the key=value approach as it’s easy to recognize and parse, you can obviously place values in labels by following any common format you define. For the Freifunk Hochstift Backbone I introduced labels of the format batman_connect_<instance_name> (e.g. batman_connect_pad-cty) enable B.A.T.M.A.N. adv. overlay for a given instance on a tagged interface.
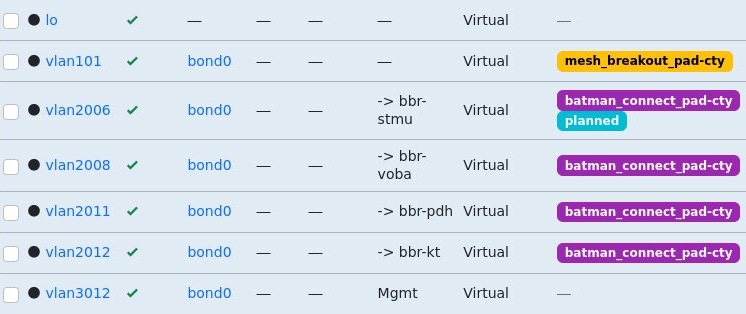
NetBox interface overview with Tags
The next level – prefix lists
Oliver – takt – Geiselhardt-Herms took this to the next level in a previous role and created tags with a hierarchical naming structure for prefixes, following the format prefix-list=key1:key2:key3…
The idea is that any prefix with a prefix-list tag with value key1:key2:key3 is added into the prefix lists name
key1:key2:key3
key1:key2
key1
An example structure could be
<VRF>:<purpose>:<label>, e.g. INTERNET:CUSTOMER:<customer name here>
<purpose>:<region>:<device>, e.g. CUSTOMERS:DE:core01.fra01
etc.
This obviously can be extended to more levels if it were to be required.
Recently I wrote a scripts which aids in provisioning things inside our network, which will do some sanity checks and if all is good set up a number of things (prefixes, IPs, sub-interfaces, IPs on them, etc.). The reason to do this inside a script is to do this in an atomic operation, so either the full provision process is done, or nothing is changed at all.
If the sanity checks fail (invalid input, trying to create something with overlapping resources, etc.) the script should fail and ideally report a clear error message one what was wrong, which should be reported to the caller (via API).
Now I was looking into exiting the script on an error and only found the option to throw any Exception which will produce a stack trace of all internal Exceptions which had been caught and handled. There is a AbortTransaction Exception, which allows to terminate the script and thereby the DB transaction, but it was not designed to carry an error message.
Looking into the code it seemed like adding support to gracefully abort a would be rather straight forward to add, so I did (issue, PR). Today the PR got merged and NetBox v3.4.4 (and later) includes the AbortScript exception to elegantly abort scripts, which you can use like this:
from utilities.exceptions import AbortScript
if some_error:
raise AbortScript("Some meaningful error message")
A great new book on Network Automation with Go just dropped recently and if you want to get into automation parts of your network or wants to start doing so with Go, it’s definitely for you!
Network Automation with Go book
It contains a lot of background on the Golang programming language, its concepts and how to use them to build reliable, scalable, testable, and observable applications. The authors also discuss Network Automation and configuration management approaches in general, and dig into APIs and network monitoring.
Recently we were wondering why node_exporter, in all the nice metrics it exposes about a Linux system, does not show if a Linux network interface is configured to be UP or DOWN, but only the operational state. So we started digging…
On the CLI, using iproute2 tooling, the operational state is shown explicitly, for example in the 2nd column in the following output:
$ ip -br l
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP> eth0 DOWN aa:bb:cc:dd:ee:ff <NO-CARRIER,BROADCAST,MULTICAST,UP> wlan0 UP 00:08:15:ab:cd:ef <BROADCAST,MULTICAST,UP,LOWER_UP> eth1 DOWN 01:31:17:00:47:11 <BROADCAST,MULTICAST> ffho-ops UNKNOWN <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP>
If you look closely you can see that the administrative state is encoded within the last column, namely it’s up if the keyword “UP” is part of the list, and down otherwise.
We started digging through /sys/class/net/* but didn’t find any entry which seemed to correspond to the administrative state of the interface. Digging further the flags caught my eye and playing with an interface revealed that the last bit seemed to indicate if the interface should be UP or DOWN.
The use of dynamic routing protocols – mainly IS-IS, OSPF and BGP – is quite common in contemporary networks, even on the host networking stacks. In some situations it is desirable to not only control the path packets will take to any given destination, but also the source address of locally sourced traffic.
By default Linux systems will use the primary IP address of the egress interfaces, which has global scope and has the same address family of the flow in question. This decision can be overridden per destination by setting the src attribute of a route to a specific locally configured IP address, for example:
ip route add 2001:db8:0815::/48 via 2001:db8:1::1 src 2001:db8::42
For routes installed by a routing daemon this has to happen inside the routing daemon, so the the NETLINK call will know about the source address to set. For bird this is rather straight forward, for FRR it took me – and apparently others – a bit of time to find the right knobs, so I’ll document both ways here for future me and like present you looking for it 🙂
bird
In bird that’s fairly simple and can be done via the export filter of protocol kernel. In bird 1 this could look like this:
define LO_IP = 192.0.2.42;
protocol kernel { scan time 20; import none; export filter { # <Apply any required filtering here/>
# Set src attr of all routers installed in FIB to LO_IP krt_prefsrc = LO_IP; accept; }; }
For bird 2 this has to happen inside the address family specific configuration:
# Set src attr of all routers installed in FIB to LO_IP krt_prefsrc = LO_IP; accept; }; }
FRR
For FRR the configuration is a little bit more involved and requires a route-map to be applied to the protocols the routes are learned from! So if you want to set the source address for routes learned from OSPF this would look like this:
route-map set-loopback-src-ip permit 1 set src 192.0.2.42 ! ip protocol ospf route-map set-loopback-src-ip
If you want to filter on which prefixes this applies, this could be done by adding a prefix list into the route-map, e.g.
route-map set-loopback-src-ip permit 1 match ip address prefix-list YOUR_PREFIX_LIST set src 192.0.2.42
If you run OSPF + BGP and want the source address to be set for both protocols, you need to add an additional line to the config example from above:
In the early days into the project we didn’t have much funds but thankfully received quite some donations in terms of old hardware as well as money. As we were young and didn’t know what we know today, we went down quite some different roads, made lots of experiences along the way, eventually reaching the setup we have today. This posts lists most the platforms we used within the last years, basically only leaving out early wireless platforms and sponsored server machines.
As most Freifunk communities rely heavily on products from the portfolio of Ubiquiti Networks, quite some devices will be covered. In the following I will just call them ubnt.
A while ago we had a discussion in #DENOG on how to best model CWDM MUXes in NetBox/Nautobot, so they can be used to build a network topology, which can be leveraged for holistic automation, and are prepared for augments, repairs and network changes.
8Ch CWDM MUX
“Natural” way of modelling
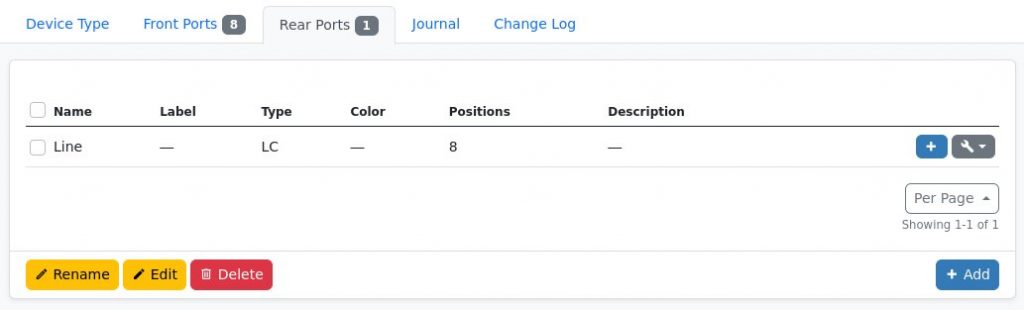
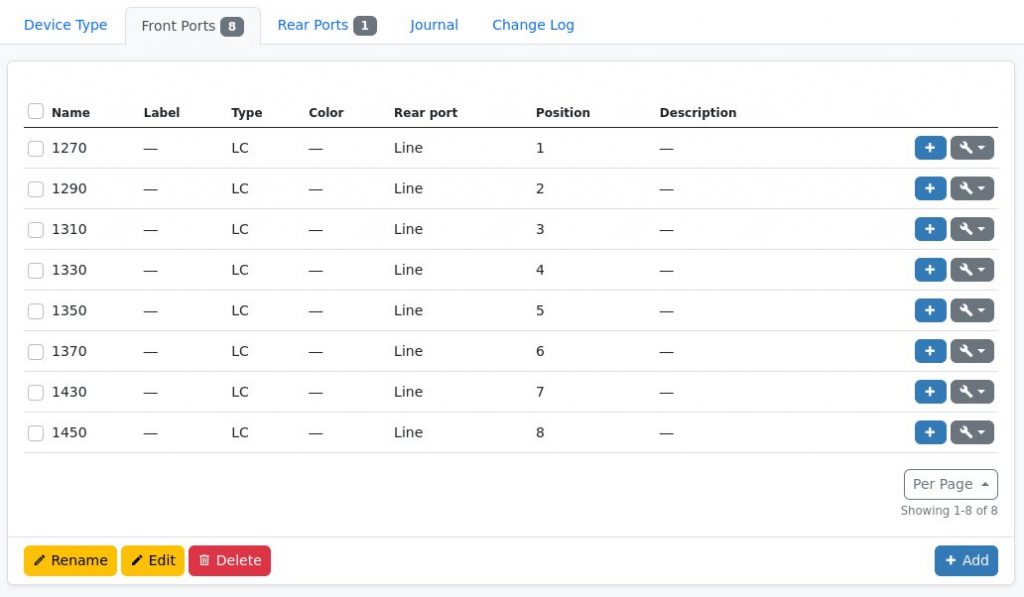
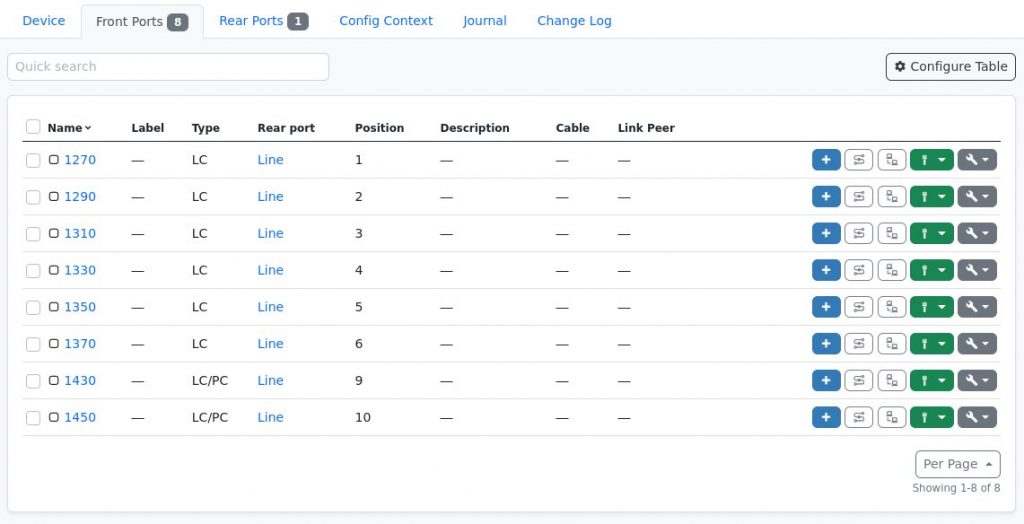
The “natural” way of modelling for example an 8Ch CWDM MUX – as shown above – would be do create a DeviceType containing one RearPort with 8 position as well as 8 FrontPorts which map to one position each. So logically this would look like the following
Inside NetBox the Rear Port and Front Ports view of the DeviceType could look like this
One Rear Port with 8 positionsEight Front Ports mapped to one position each
This model works absolutely, allows tracing connections through the MUXes etc. as long as we always use exactly the same MUX on both ends off the fiber for one WDM setup.
Limitations
If one MUX would decay over time and needs to be replaced by another model e.g. due to supply chain issues, which for example might have 10 channels and does not skip 1390 and 1410, the mapping would fail. This obviously would also be the case if for an expansion the setup should be changed to 18Ch MUXes and this could only be done one side after another.
Universal way of modelling
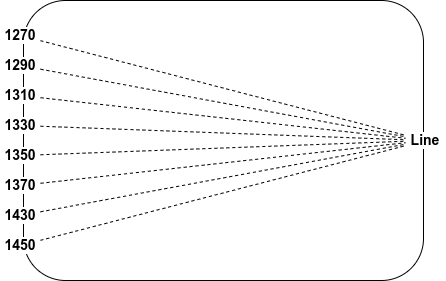
As the ITU CWDM standard only defines 18 CWDM channels in total with a fixed spacing of 20nm we can use one simple trick to overcome this limitation: Always define all 18 positions and only map the existing Front Ports to their associated position as shown in the following table.
Position
Channel
1
1270
2
1290
3
1310
4
1330
5
1350
6
1370
7
1390
8
1410
9
1430
10
1450
11
1470
12
1490
13
1510
14
1530
15
1550
16
1570
17
1590
18
1610
So the Front Ports of the MUX shown above would be mapped to positions 1-6, 9, and 10. This way all CWDM MUXes can be connected in NetBox/Nautobot and all channels which exist on both ends can be connected and traced through.
Eight Front Ports mapped to one their associate (existing) positions
What about DWDM?
For DWDM systems this obviously would be somewhat harder given the bigger amount of possible channel, especially when different spacing options (25, 50, 100GHz) are taken into account. It would be possible though to go for 160 positions and map the channels accordingly given strict adherence to a to be predefined map.
In the past months and years I’ve had a number of great discussion with a lot of fantastic networking people on how to (not) do network automation (at scale), what worked for them and what didn’t. At a smaller scale I made quite some experiences myself at previous roles as well as consulting engagements and in particular by building and operating the Freifunk Hochstift community ISP network plus it’s SDN. This article is the distilled result of those discussions and experiences and might be somewhat opinionated.
At DENOG13 I held a workshop Fun with PBR, VRFs and NetNS on Linux (in German) where I showcased forwarding IP packets within a VRF via static MPLS LSPs. I’ve been asked to publish the configuration for this lab, so here we are 🙂
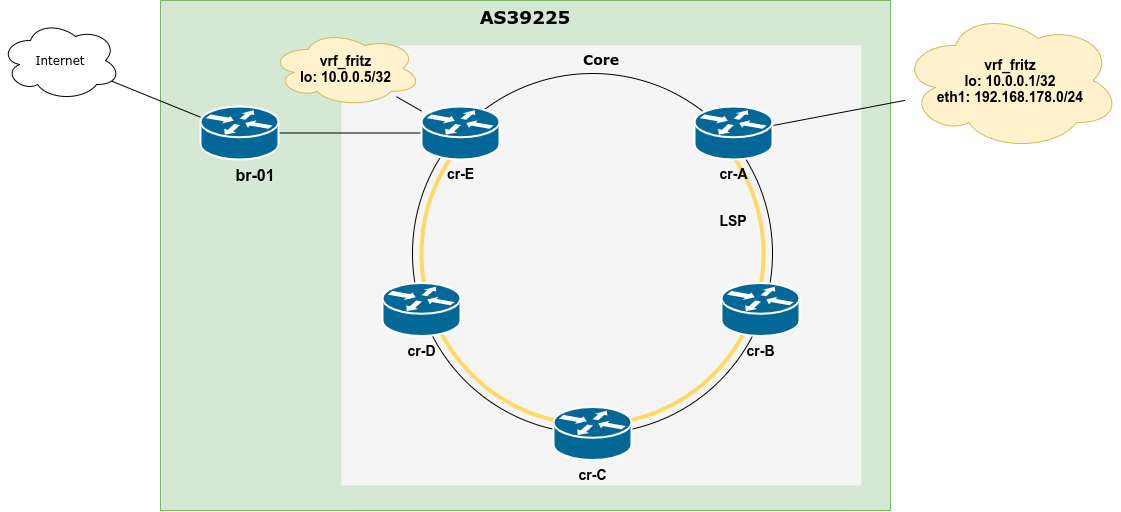
Consider the following topology consisting of a core ring build with 5 routers, a border router (br-01) connected to core router E (cr-E) as well as to the Internet. All routers take part of OSPF area 0 and run iBGP with br-01 as the route reflector which is providing a default route. This is the same setup used for most of the FrOSCon Network Track.